Select below to see ROVER versus GVL Zero-Shot progress prediction and frame-level reasoning on videos from succcessful and unsuccessful trajectories across single-stage and multi-stage tasks. For the tasks from simulation, the videos are separated into levels based on the amount of the task completed during the video. The amount of non-expert behavior in the video increases as the level decreases. The highest-level trajectories for each task show full task completion with near-expert behavior. The level 1 trajectories do not achieve any part of the task. The task progress values generated by ROVER and GVL are shown in yellow and blue, respectively. The ground-truth progress values are shown in gray.
ROVER is a recursive framework for reasoning over camera video that decomposes a task into subtasks to maintain a compact temporal context, improving reasoning accuracy and efficiency. Instead of generating a long, single line of reasoning spanning all timesteps of the video input for a task attempt (e.g., opening a microwave door), ROVER decomposes the task and generates a separate line of reasoning for each subtask (e.g., grasping the microwave door handle). When a subtask is complete, the corresponding line of reasoning terminates and a new one is created for the video input for the next subtask (e.g., pulling the door open). We show that the decomposition not only improves accuracy by focusing the reasoning on relevant temporal segments, but also enables the implementation of a subtask-specific sliding context window, which further reduces the number of frames the model must reason over at each moment of a trajectory.

We evaluate ROVER, implemented using an in-context learning approach, in the setting of robotic manipulation tasks using a large-scale dataset of videos collected from robot-mounted and third-person camera viewpoints during both successful and unsuccessful task attempts.
We create this dataset by automatically perturbing expert demonstrations collected in RoboCasa to produce diverse trajectories, ranging from near-optimal to fully random action sequences.
In addition, we compute ground-truth task progress estimates at each timestep based on geometric distance to goal states.
The generated dataset includes 543 videos across 27 tasks, each collected in a random kitchen scene.
We leverage this dataset to evaluate ROVER across three benchmarks for embodied reasoning over camera video:
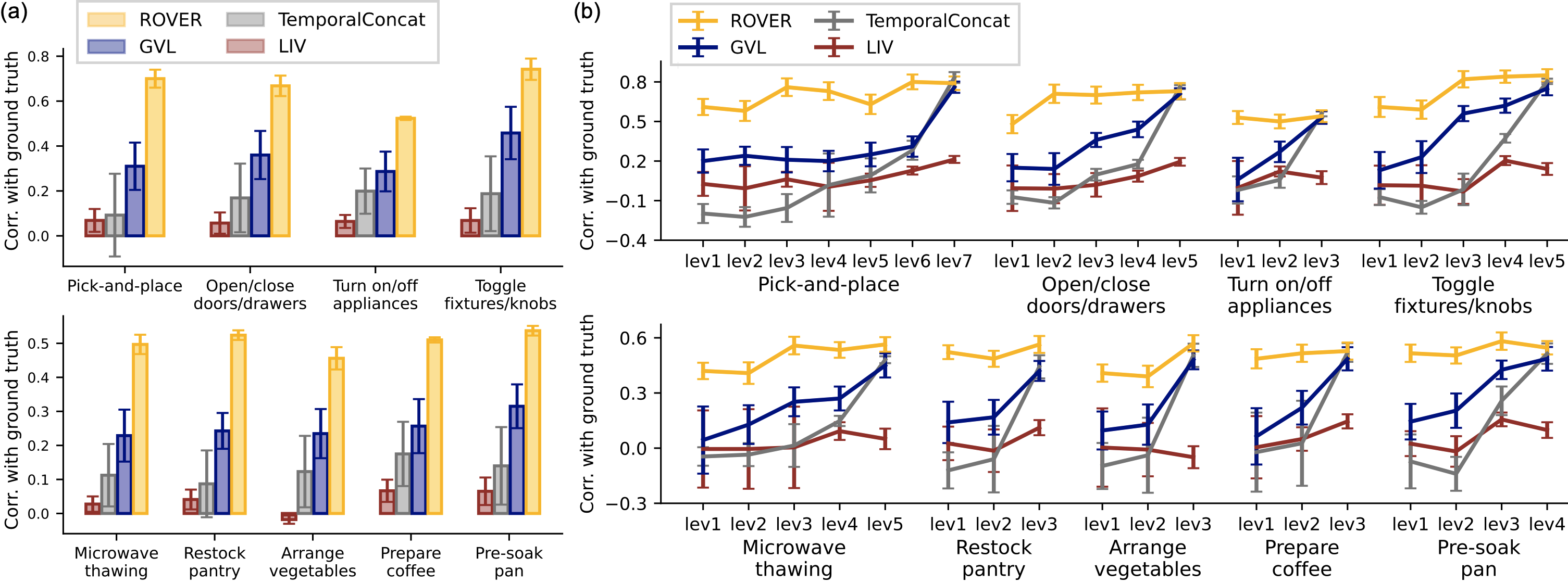
For videos that exhibit task completion with near-expert behavior (i.e., the highest level within each task group), ROVER, GVL, and TemporalConcat achieve a Pearson correlation with ground-truth progress estimates near or above 0.5 across most task groups. However, for videos with incomplete task execution, GVL and TemporalConcat deviate significantly from the ground truth. These deviations become more extreme as the trajectory level decreases (i.e., as the number of non-expert states in the video increases).
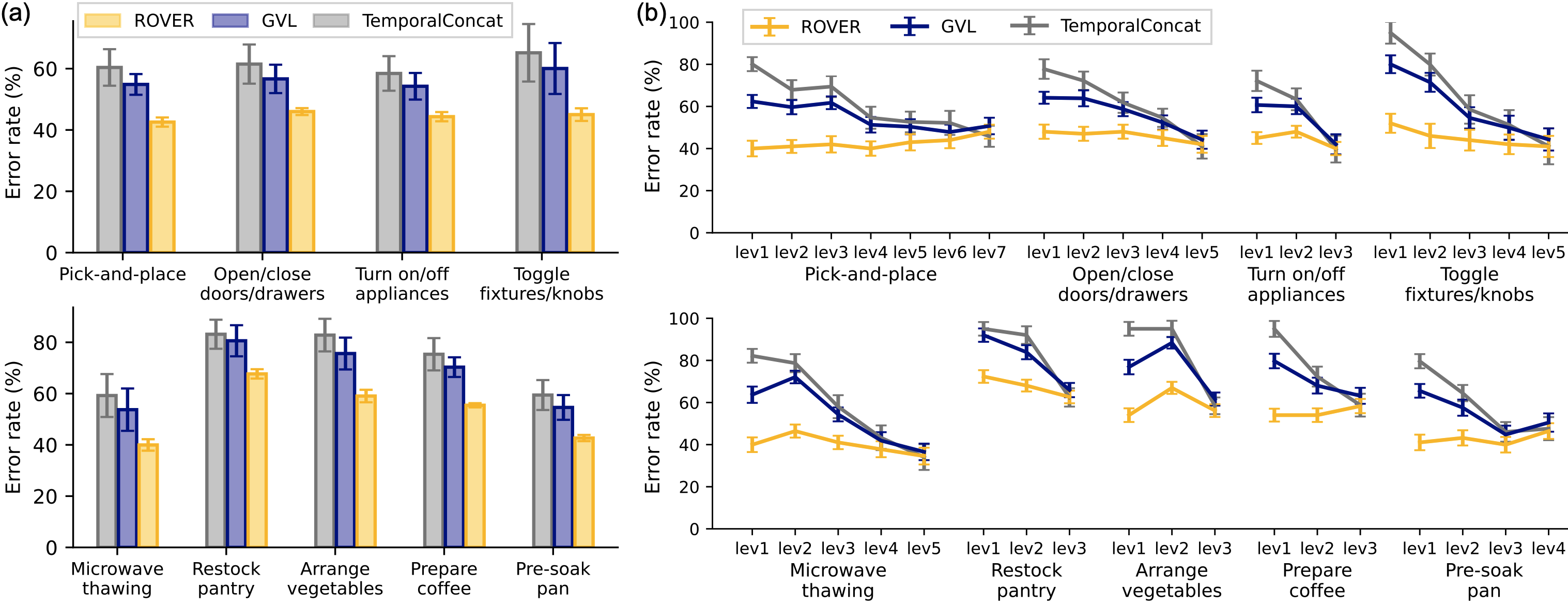
The reasoning error rate is similar for all methods for videos containing near-expert task completion. However, as videos deviates from expert behavior, the error rate increases significantly for GVL and TemporalConcat. These trends mirror the results of the progress prediction task, suggesting that errors in progress prediction result from errors in the natural language descriptions of the frame that precedes the progress prediction at each timestep. We further evaluate the nature of these errors in the video QA analysis below.
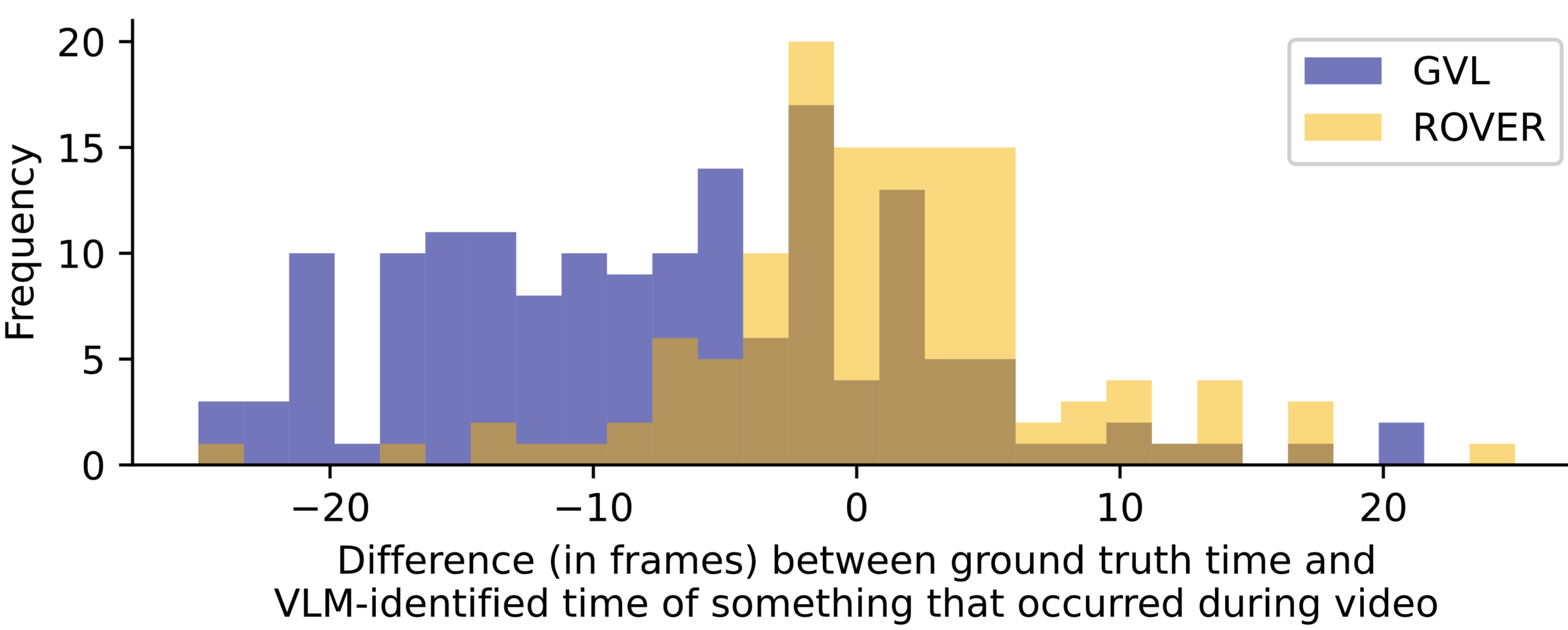
ROVER shows significantly higher accuracy than GVL and TemporalConcat on the video QA benchmark across all task groups. The video QA results reveal a hallucination problem with GVL and TemporalConcat, where the VLM is likely to state that an event occurred during a video, regardless of whether it actually occurs. This is illustrated by the low precision (20 to 50\%) and high recall values (near 100\%) across all task groups for GVL and TemporalConcat. The hallucination problem is also highlighted in the analysis of the distance between the time when something occurs in a video and the time when the VLM states that it occurred. We see that, even when GVL correctly states something occurs during a video, it is much more likely than ROVER to state this prematurely (as shown by the negative frame difference in the figure below).
@inproceedings{schroeder2025rover,
author = {Schroeder, Philip and Biza, Ondrej and Weng, Thomas and Luo, Hongyin and Glass, James},
title = {ROVER: Recursive Reasoning Over Videos with Vision-Language Models for Embodied Tasks},
booktitle = {39th Conference on Neural Information Processing Systems},
year = {2025}
}
